
Nasze ostatnie analizy w Centrum Kompetencyjnym Business Intelligence dotyczą bardzo aktualnego tematu, który za razem jest bardzo interesujący. Każdy z nas na pewno śledzi na bieżąco zestawienia zarażeń COVID-19. Zatem zapraszamy Was do skorzystania z naszego raportu i analizy bieżącej sytuacji, wykorzystując dane z wiarygodnych źródeł.
Nasze dane historyczne pochodzą z repozytorium Github tworzonego przez Johnson Hopkins University Center For System Science and Engineering (JHU CSSE). Szczegóły na temat źródła danych można znaleźć tutaj. Dane z dwóch ostatnich dni są pobierane ze strony Worldometer, gdzie także na bieżąco podane są źródła agregowanych danych.
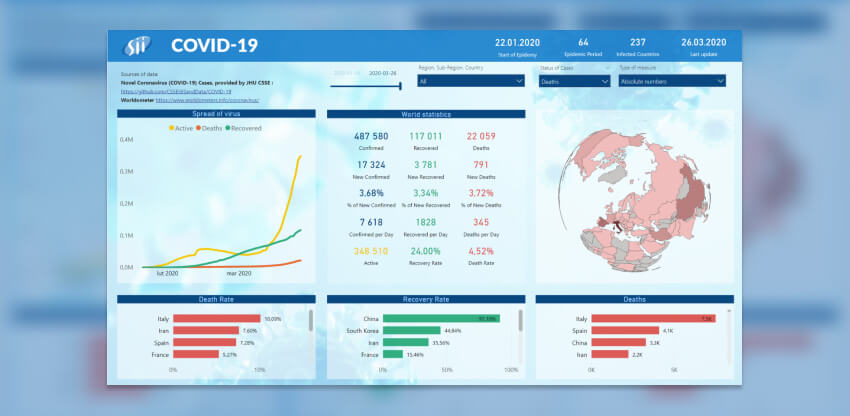
Interaktywny raport – pandemia COVID-19 – Jak analizować prezentowane dane?

Raport Intro pokazuje najważniejsze dane w skali całego świata. Na mapie można zobaczyć najważniejsze statystyki, rozwój wirusa w czasie i przestrzeni. Ranking krajów wg wskaźnika śmiertelności (Death Rate) lub wskaźnika wyzdrowień (Recovery Rate) oraz wg innych miar, które można wybrać z listy Status of Cases. Wartości na mapie mogą być przedstawione jako wartości absolutne lub jako ilość przypadków na 100 tys. populacji w danym kraju.

Raport World Regions przedstawia rozprzestrzenie się wirusa na poszczególnych kontynentach. Na mapie pokazujemy także kolorami jak długo już trwa epidemia, a wielkość okręgu pokazuje skalę zakażenia w zależności od wybrania odpowiedniego statusu przypadku (Status of Cases) i typu miary.
Wykresy słupkowe można eksplorować w dół zaczynając od kontynentu, przez region do konkretnego kraju.
Używając suwaka z datą na obydwu raportach można przeglądać, jak sytuacja zmieniała się w czasie.
Na każdym z wykresów, gdzie można zaznaczyć kraj można klikając prawym przyciskiem myszy wybrać raport szczegółowy dla danego kraju. Używamy do tego funkcjonalności pięknie brzmiącej w języku polskim drążenie wskroś? (Drillthrough). Najeżdżając myszką na kraj pojawia się także etykieta narzędzia (tooltip) na którym są widoczne dodatkowe informacje wraz z wykresem zmian wartości w czasie wraz z 10 dniową prognozą.

Poniżej raport szczegółowy dla Włoch, który wyświetla się po wybraniu drążenia wskroś wybranego kraju.

Znajdują się na nim najważniejsze statystyki i wykresy dla danego kraju. Mierniki w prawym górnym rogu pokazują ilość przypadków w zależności od wybranego statusu w porównaniu do maksymalnej liczby przypadków w regionie (Subregion), jako cel jest ustawiona średnia w danym regionie.
Epidemia koronawirusa zaczynała się w różnych krajach w różnym czasie, dlatego zależało nam na pokazaniu rozwoju wirusa wg dni kiedy się on zaczął, ponieważ na osi czasu krzywe były przesunięte.
Po pierwszej analizie danych zauważyliśmy, że trzeba także uwzględnić czas, w którym znacząca liczba zarażonych pojawiła się w tym samym czasie, ponieważ istniały kraje, w których pierwsze przypadki były wykryte dość wcześnie i były to osoby przyjeżdżające z zewnątrz. Zbudowaliśmy tak model aby można było dynamicznie zmieniać liczbę przypadków od jakiej chcemy porównywać kraje.

W raporcie Significant Days możemy porównać jak w danych krajach rozprzestrzenia się wirus, a może dokładniej ile przypadków zostało wykrytych. Jeśli pojawią się dane o ilości testów w danych krajach, warto będzie dodać te dane do modelu.
Polska jest tu szczególnie wyróżniona (linia przerywana) żebyśmy mogli na bieżąco śledzić, czy zamknięcie nas wszystkich w domach dało oczekiwany skutek i gdzie jesteśmy w porównaniu do krajów, gdzie sytuacja jest już dramatyczna. Jak widać po 12 dniach od pierwszych 100 dni nie jest tak źle. Obok wykresu liniowego jest tabelka z krajami znajdującymi się na wykresie w kolejności od największej ilości przypadków na koniec zaznaczonego okresu. Wykres można oglądać w skali logarytmicznej lub liniowej. Dane mogą być także przedstawione w wartościach absolutnych lub skorelowanych z populacją w danym kraju (Per 100K Population), wtedy otrzymamy wartości podzielone przez 100 tys. populacji danego kraju.
Na koniec dodaliśmy dwa raporty pokazujące dane w formie tabelarycznej. Raport Countries by day of epidemy pozwala porównać sytuację w jakiej znajdowały się poszczególne kraje na konkretny dzień trwania epidemii, gdzie można wyznaczyć od jakiej ilości potwierdzonych zakażeń uznajemy jako pierwszy dzień epidemii.

W raporcie Countries by date of epidemy możemy sprawdzić sytuację na bieżący dzień kalendarza lub cofnąć się w czasie i sprawdzić jak wyglądała sytuacja w poszczególnych krajach wcześniej.

W trakcie przygotowywania tego artykułu i tworzenia raportów wciąż pojawiają się nowe pomysły wizualizacji danych i za pewne w najbliższym czasie pojawią się nowe.
Dane źródłowe
Przystępując do stworzenia własnego raportu, chcielibyśmy jak najszybciej zobaczyć efekt, popróbować różnych wizualizacji, zastosować filtry, jakich wcześniej nie widzieliśmy. Nie dajmy się jednak pokusie pójścia na skróty, bo z doświadczenia wynika, że to zawsze do nas wróci i zwielokrotni nakład pracy. Poświęćmy trochę więcej czasu danym źródłowym.
Dane dotyczące wcześniejszych dni pobieramy ze strony:
https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series
Są to trzy pliki .csv

Dlaczego, pobieramy stąd tylko dane historyczne, czyli starsze niż wczorajsze? Ponieważ są aktualizowane rzadko i nieregularnie. Musimy do nich dołączyć inne źródło, czyli:
https://www.worldometers.info/coronavirus/

Power BI posiada świetne narzędzia do web scrappingu, więc po kliku kliknięciach, mamy dane w tabelach. No właśnie, w tabelach… o różnej strukturze. Musimy je przekształcić i połączyć, pamiętając że każda struktura może ulec zmianie wprowadzonej przez naszego dostawcę danych. Co powiecie np. na zmianę plików .csv na dzień przed opublikowaniem raportu? To wydarzyło się naprawdę. Przecież nikt nie obiecywał, że nie będzie zmian, w końcu dane są „gorące” i każdy chce je oglądać na swój sposób.
No dobrze, mamy 5 źródeł, nie 2 jakby się mogło wydawać. Coś co zadziała na plik …confirmed_global.csv, niekoniecznie musi zadziałać w …recovered_global.csv. Takim przypadkiem w dniu 26.03.2020 przed południem była różnica, w zapisaniu daty, jeden plik miał daty w formacie d/mm/rr, drugi d/mm/rrrr. W momencie, gdy to czytasz, formaty mogą być już spójne.
Przystępujemy do przekształceń, korzystając z pełni dobrodziejstw narzędzia jakim jest Power Query Editor. Nie będziemy rozpisywać się szczegółowo, jak przekształcone zostały te źródła, ale ogólna zasada jest taka, że pilnujemy kolejności, bo nieprawidłowa kolejność może wydłużyć ładowanie. To nie parsowanie SQL, gdzie mamy szereg wbudowanych narzędzi optymalizujących zapytanie. W zamian dostajemy kontrolę nad każdym krokiem przekształcenia i możemy je modyfikować i przestawiać. Nie zapominajmy przy tym o czytelnym nazywaniu kroków, pomoże nam to szybciej w przyszłości wprowadzić zmiany w procesie. Ogólne zasady mówią o tym, żeby zacząć od odchudzenia tabeli, najpierw redukcja kolumn (zakładamy że mają już jakieś nazwy), potem wierszy (wcześniej unpivot, jeżeli jest potrzeba). Potem przyglądamy się danym w komórkach, możliwe że trzeba dokonać przekształceń, wstępnych kalkulacji, oczyścić teksty, dodać kolumny, zmienić typ, itd. Na koniec jeszcze raz patrzymy czy potrzebujemy wszystkich kolumn, układamy je w pożądanej kolejności i voilà.
Jeżeli w przyszłości zajdzie potrzeba wprowadzenia zmian, to pamiętajmy, że każdy krok to instrukcja języka M, którą możemy podejrzeć dla każdego kroku tutaj:

A całe query, możemy zobaczyć tutaj:

Przy czym nie polecamy edycji w Advanced Editor, ponieważ stracimy podział na kroki.
No dobrze, łączymy te nasze 5 tabelek w jedną, powiedzmy faktową i temat przygotowania danych źródłowych się kończy, prawda? Otóż, nieprawda. Pomińmy tu etap modelowania, załóżmy, że mamy już wszystkie wymiary, relacje, miary. Robimy wizualizację w postaci mapy i okazuje się, że taki jeden kraj graniczący od południa z Polską jest białą plamą, nieskażoną wirusem, czy aby na pewno?

No przecież, dane w źródłach są:

Widzicie to? Od tej pory należy przejrzeć wszystkie białe plamy na mapie świata, sprawdzić wszystkie nazwy krajów jakie dostaliśmy ze źródeł i dopasować je do mapy, dosłownie zmapować ?.
Pożądany efekt uzyskaliśmy tworząc w Power Query funkcję, zbierającą wszystkie niezgodności w serię poleceń replace value:

…

Teraz możemy użyć serii przekształceń zarówno po stronie wymiaru Location, jak i tabeli faktowej, bądź jeszcze przed nią, jeżeli uznamy to za lepsze rozwiązanie.
Ale to nie koniec z poznawaniem geografii politycznej świata. Widzieliście pewnie inne raporty z przedstawianiem danych na mapie. Zwróciliście uwagę, czy np. Grenlandia jest tam zajęta przez wirus? Przecież mamy dla niej dane:

Musimy zrobić listę wyjątków, gdzie Province/State chcemy żeby było traktowane na równi z Country. W tym celu w Power Query robimy listę, najlepiej statyczną, bez powiązań z danymi źródłowymi, nie chcemy tzw. Circular dependency.

a naszym nowym Country Region staje się kolumna powstała w ten sposób:

Na koniec sprawdzamy, czy wszystkie lokalizacje z danych da się przedstawić na mapie i czy wszystkie tak naprawdę warto przedstawiać w zestawieniach. Uważny czytelnik zwrócił uwagę na listę i zawarte na niej dane ze słowem Princess w nazwie. Czy to kraj, czy prowincja, czy jakaś mała wyspa? Nie, to statek wycieczkowy ?. Na chwilę obecną te dane nie są ładowane do raportu, ale usuwane są na jednym z ostatnich etapów, być może zmienimy zdanie i będziemy je ładować. Ładujemy model, kontrolujemy czas ładowania i mamy nadzieję, że struktura danych źródłowych nie będzie zmieniać się zbyt często. No, ale na wszelki wypadek cały czas kontrolujemy źródła i przeglądamy wykresy w poszukiwaniu niezgodności, przy okazji coraz więcej dowiadując się o rozprzestrzenianiu się COVID-19.
Po załadowaniu danych do Power BI musimy stworzyć model. Nie mamy żadnej bazy danych więc zakładamy, że naszą bazą danych będzie plik .pbix, który dodamy do listy zestawów danych na serwisie Power BI. Raporty będą podłączane do opublikowanego zestawu danych, dzięki temu mamy jedno źródło danych. Jeden model, a w nim sprawdzone i przetestowane miary. Jeśli znajdziemy jakiś błąd w modelu lub będziemy chcieli go zmienić wystarczy zmienić plik źródłowy z zestawem danych i podmienić go we współdzielonym katalogu OneDrive.
Dane jakie znajdują się w plikach źródłowych przedstawiają całkowitą wartość Potwierdzonych zakażeń (Confirmed), przypadków śmiertelnych (Deaths) i przypadków wyzdrowień (Recovered) dla danego kraju i dnia. To powoduje, że praktycznie nie mamy w modelu prostych miar używających agregację sumującą.
Poniżej przedstawiamy model jaki na tę chwilę został stworzony.

Stworzone miary zgrupowane w 2 grupy World Statistic i Statistic posłużyły do stworzenia prezentowych wyżej raportów.
To tyle ile udało nam się zrobić w ciągu kilku dni. Pracujemy nad innymi ciekawymi wizualizacjami, które dodamy w najbliższym czasie. Pewnie powstanie kolejny materiał na temat tworzenia własnych wizualizacji. ?
Mieliśmy także trochę problemów z odświeżaniem danych z pliku .pbix umieszczonym w serwisie OneDrive. Chyba natrafiliśmy na błąd, który trzeba zgłosić do Microsoftu, ale to temat na kolejny artykuł. ?
Analizę i artykuł przygotowali specjaliści z Centrum Kompetencyjnego BI w Sii.
















Zostaw komentarz