






























Our recent analyses at Business Intelligence Competency Center relate to a currently pressing topic and a very interesting one at the same time. Each of us is certainly following COVID-19 infection reports regularly. Therefore, we invite you to use our report and analyze the present situation, using data from reliable sources.
Our historical data comes from the Github repository created by Johns Hopkins University Center For System Science and Engineering (JHU CSSE). Details about the data source can be found here. Data from the last two days are downloaded from Worldometer page where aggregated data sources are also provided on an ongoing basis.
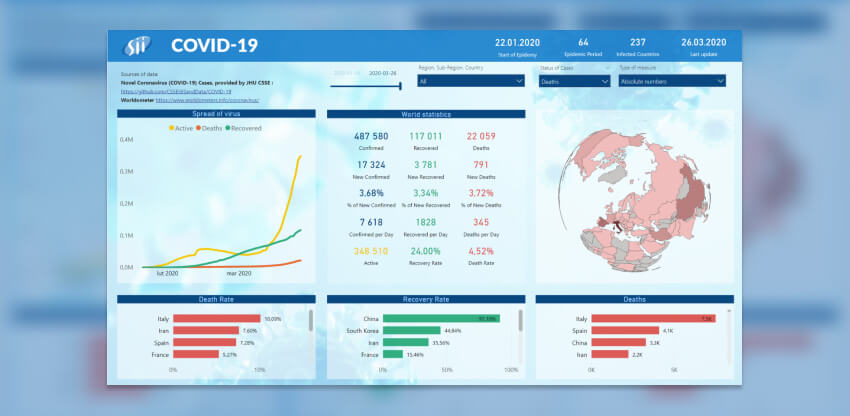
Interactive report – COVID-19 pandemic – How to analyze the presented data?

The Intro report shows the most important data worldwide. On the map, one can see the most important statistics, the development of the virus chronologically and geographically. Ranking of countries according to Death Rate or Recovery Rate and other parameters that can be selected from the Status of Cases list. The values on the map can be presented as absolute values or as the number of cases per 1M population in a given country.

The World Regions report presents the spread of the virus on individual continents. The map also uses colours to display how long the epidemic has been going on, and the size of the circle shows the scale of the infection depending on the appropriate status of cases and the type of parameter.
Bar charts can be explored downwards starting at the continent level, through the region to a specific country.
Using the date slider on both reports, you can view how the situation has changed over time.
On each of the charts, where you can select the country, use right-click to select the detailed report for a given country. For this, we use a functionality called Drillthrough. Once you hover your mouse over a country, a tooltip appears showing additional information along with a graph of value changes over time with a 10-day forecast.

It contains the most important statistics and charts for a given country.

The meters in the upper right corner show the number of cases depending on the status selected compared to the maximum number of cases in the region (Subregion) – the target is set as the average in the region.
The coronavirus outbreak began in different countries at different times, therefore, we wanted to show the virus development by days when it started, as the curves were shifted on the time axis.
After the first analysis of the data, we noticed that it was also necessary to take into account the time when a significant number of infected people appeared at the same time since there were countries where the first cases were detected quite early – pertaining to an inflow of foreigners. We have built a model so that you can dynamically change the number of cases from which you want to compare countries.

In Significant Days report, we can compare how the virus spreads in given countries, and more precisely how many cases were detected. If there is data about the number of tests in given countries, it will be worth adding this data to the model.
Poland is particularly distinguished here (dotted line) so that we can keep track of whether closing all of us in homes gave the expected result and where we are compared to countries where the situation is already dramatic. As you can see after 12 days from the first 100 days it is not so bad. Next to the line chart, there is a table with countries on the chart in order from the largest number of cases at the end of a selected period. The graph can be viewed on a logarithmic or linear scale. The data can also be presented in absolute values or correlated with the population in a given country (per 1M Population), then we will get the values divided by 1M population of the country.
Finally, we added two reports showing data in tabular form. Countries by day of epidemy report allows you to compare the situation in which individual countries were on a specific day of the epidemic, where you can determine from what amount of confirmed infections we consider as the first day of the epidemic.

In the report Countries by date of epidemy, we can check the situation on the current calendar day or go back in time and see what the situation in individual countries looked like earlier.

During the preparation of this article and the creation of reports, new ideas of data visualization are constantly emerging and new ones will appear soon.
Source data
During the preparation phase of creating own report, we strived to see the effect as soon as possible, try different visualizations, apply filters that we have not seen before. However, let us not be tempted to take a shortcut, because experience shows that it will always get back at us and multiply the workload. Let’s devote a little more time to the source data.
We collect data for earlier days from:
https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series
These are three .csv files

Why are we only collecting historical data from here, i.e. older than from yesterday? Because they are updated rarely and irregularly. We need to attach another source to them, namely:
https://www.worldometers.info/coronavirus/

Power BI includes great tools for web scrapping, so after a few clicks, we have the data in the tables. Well, in the tables … of different structures. We need to transform and combine them, remembering that each structure can be changed by our data provider. How about, for example, changing your .csv files the day before the report is published? It really happened. After all, nobody promised that there would be no changes – in the end, the data is “hot” and everyone wants to watch it in their own way.
Well, we have five sources, not two as it may seem. Something that works for the file … confirmed_global.csv does not necessarily work in … recovered_global.csv. Such a case on 26/03/2020 before noon was the difference in the date form – one file had dates in the format dd/mm/ yy, while the other in dd/mm/yyyy. By the time you read this, the formats may already be consistent.
We proceed to transformations using the full benefits of the Power Query Editor tool. We will not describe in detail how these sources have been transformed, but the general rule is that we follow the order, as the wrong order can prolong the loading. This is not SQL parsing, where we have a number of built-in query optimization tools. In return, we get control over each transformation step and we can modify and rearrange them. Let’s not forget about the legible names of steps, it will help us make changes in the process faster in the future. The general rules are to start by slimming the table, first reducing the columns (we assume that they already have some names), then the rows (previously unpivot, if necessary). Then we look at the data in the cells, you may need to make transformations, preliminary calculations, clean the texts, add columns, change the type, etc. Finally, we look again if we need all the columns, arrange them in the desired order and voilà.
If you need to make changes in the future, remember that each step is an M language instruction that you can view for each step here:

And the whole query can be seen here:

However, we do not recommend editing in the Advanced Editor, because we will lose the division into steps.
We combine our 5 tables into one, say factual and the topic of preparation of source data ends, right? Well, that’s not true. Let’s skip the modeling stage here, let’s assume that we already have all dimensions, relations, and measures. We create a visualization in the form of a map and it turns out that one country bordering Poland from the south is a white spot uncontaminated by a virus – is it really so?

Well, the data in the sources is there:

See right here? From now on, you should review all the white spots on the world map, check all the names of countries we got from the sources and do the mappings, literally match them to the map.
We obtained the desired effect by creating a function in Power Query, collecting all incompatibilities in a series of ‘replace value’ commands:

…

Now we can use a series of transformations on both the Location dimension side and the fact table, or even before it if we consider it a better solution.
But this is not the end of learning about the political geography of the world. You’ve probably seen other reports presenting data on the map. Have you noticed, e.g. Is Greenland occupied by a virus there? We have data for it:

We need to make a list of exceptions, where Province / State wants it to be treated on a par with Country. To this end, we make a list in Power Query, preferably static, without any links to the source data, we do not want the so-called Circular dependency.

and our new Country Region becomes a column formed in this way:

Finally, we check whether all locations from the data can be represented on a map and whether all of them are really worth presenting in the lists. An attentive reader drew attention to the list and the data on it with the word Princess in the name. Is it a country or a province or a small island? No, it’s a cruise ship. At the moment, this data is not being loaded into the report, but it is removed at one of the last stages – perhaps we will change our mind and load it after all. We load the model, control the load time, and we hope that the structure of the source data will not change too often. However, just in case, we constantly control the sources and browse the charts in search of incompatibilities, while learning more and more about the spread of COVID-19.
After loading the data into Power BI, we need to create a model. We do not have any database so we assume that our database will be a .pbix file, which we will add to the list of datasets on Power BI. Reports will be connected to a published dataset, so we have one data source. One model with verified and tested measures. If we find an error in the model or want to change it, it is enough to change the source file with the dataset and replace it in a shared OneDrive directory.
The data in the source files shows the total value of confirmed infections, deaths, and recoveries (Recovered) cases for your country and a given day. This makes sure that we have virtually no simple measures in the model that use aggregation.
Below, we present a model that has been created as of now.

Created measures grouped into 2 groups – World Statistic and Statistic were used to create the presentation reports above.
That’s as much as we’ve been able to do in a few days. We are working on other interesting visualizations that we will add shortly. There will probably be another material about creating own visualizations.
We also had some problems refreshing data from the .pbix file on OneDrive. Our guess is we’ve encountered an error that needs to be reported to Microsoft, but that’s the subject for another article.












Leave a comment